小李子的故事
import os, time
import urllib2, urllib, re, bs4
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import json
# list = ['BAFTA', 'Globes', 'SAG', 'Spirits', 'CC', 'Oscar']
# BAFTA=DataFrame()
# Globes=DataFrame()
# SAG=DataFrame()
# Spirits=DataFrame()
# CC=DataFrame()
# Oscar=DataFrame()
# dic = {"BAFTA":BAFTA, "Globes":Globes, "SAG":SAG, "Spirits":Spirits, "CC":CC, "Oscar":Oscar}
dic = {"BAFTA":DataFrame(), "Globes":DataFrame(), "SAG":DataFrame(), "Spirits":DataFrame(), "CC":DataFrame(), "Oscar":DataFrame()}
for key in dic.keys():
dic[key] = pd.read_json(json.loads(open(key + '.json').read()), orient='split')
print key
print dic[key].head()
BAFTA
name year BAFTA0 BAFTA1 BAFTA2
0 Hugh Grant 1995 0 0 1
1 Terence Stamp 1995 0 1 0
2 Tom Hanks 1995 0 1 0
3 John Travolta 1995 0 1 0
4 Nigel Hawthorne 1996 0 0 1
Spirits
name year Spirits0 Spirits1 Spirits2
0 Samuel L. Jackson 1995 0 0 1
1 Sihung Lung 1995 0 1 0
2 William H. Macy 1995 0 1 0
3 Campbell Scott 1995 0 1 0
4 Jon Seda 1995 0 1 0
CC
name year CC0 CC1 CC2
0 Kevin Bacon 1996 0 0 1
1 Nicolas Cage 1996 0 1 0
2 Geoffrey Rush 1997 0 0 1
3 Tom Cruise 1997 0 1 0
4 Jack Nicholson 1998 0 0 1
Oscar
name year Oscar0 Oscar1 Oscar2
0 Tom Hanks 1995 0 0 1
1 Morgan Freeman 1995 0 1 0
2 Nigel Hawthorne 1995 0 1 0
3 Paul Newman 1995 0 1 0
4 John Travolta 1995 0 1 0
SAG
name year SAG0 SAG1 SAG2
0 Tom Hanks 1995 0 0 1
1 Morgan Freeman 1995 0 1 0
2 Paul Newman 1995 0 1 0
3 Tim Robbins 1995 0 1 0
4 John Travolta 1995 0 1 0
Globes
name year Globes0 Globes1 Globes2
0 Tom Hanks 1995 0 0 1
1 Morgan Freeman 1995 0 1 0
2 Paul Newman 1995 0 1 0
3 Brad Pitt 1995 0 1 0
4 John Travolta 1995 0 1 0
award_list = dic['BAFTA']
for x in ['Globes', 'SAG', 'Spirits', 'CC', 'Oscar']:
award_list = pd.merge(award_list,dic[x], how='outer', on=['name','year'])
award_list.head()
| name | year | BAFTA0 | BAFTA1 | BAFTA2 | Globes0 | Globes1 | Globes2 | SAG0 | SAG1 | SAG2 | Spirits0 | Spirits1 | Spirits2 | CC0 | CC1 | CC2 | Oscar0 | Oscar1 | Oscar2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Hugh Grant | 1995 | 0 | 0 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | Terence Stamp | 1995 | 0 | 1 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | Tom Hanks | 1995 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 0 | 1 |
| 3 | John Travolta | 1995 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | 0 | 1 | 0 |
| 4 | Nigel Hawthorne | 1996 | 0 | 0 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
# Globes = pd.read_json(json.loads(open('Globes.json').read()),orient='split')
# BAFTA = pd.read_json(json.loads(open('BAFTA.json').read()), orient='split')
# SAG = pd.read_json(json.loads(open('SAG.json').read()),orient='split')
# Spirits = pd.read_json(json.loads(open('Spirits.json').read()), orient='split')
# CC = pd.read_json(json.loads(open('CC.json').read()),orient='split')
# Oscar = pd.read_json(json.loads(open('Oscar.json').read()),orient='split')
# award_list = BAFTA
# for x in [Globes, SAG, Spirits, CC, Oscar]:
# award_list = pd.merge(award_list,x, how='outer', on=['name','year'])
# award_list
Globes=dic['Globes']
Globes[Globes['name']=='Leonardo DiCaprio']
| name | year | Globes0 | Globes1 | Globes2 | |
|---|---|---|---|---|---|
| 18 | Leonardo DiCaprio | 1998 | 0 | 1 | 0 |
| 41 | Leonardo DiCaprio | 2003 | 0 | 1 | 0 |
| 50 | Leonardo DiCaprio | 2005 | 0 | 0 | 1 |
| 61 | Leonardo DiCaprio | 2007 | 0 | 1 | 0 |
| 62 | Leonardo DiCaprio | 2007 | 0 | 1 | 0 |
| 74 | Leonardo DiCaprio | 2009 | 0 | 1 | 0 |
| 86 | Leonardo DiCaprio | 2012 | 0 | 1 | 0 |
award_list['BAFTA0']=award_list['BAFTA0'].fillna(1)
award_list['Globes0']=award_list['Globes0'].fillna(1)
award_list['SAG0']=award_list['SAG0'].fillna(1)
award_list['Spirits0']=award_list['Spirits0'].fillna(1)
award_list['CC0']=award_list['CC0'].fillna(1)
award_list=award_list.fillna(0)
# award_list['BAFTA1']=award_list['BAFTA1'].fillna(0)
# award_list['Globes1']=award_list['Globes1'].fillna(0)
# award_list['SAG1']=award_list['SAG1'].fillna(0)
# award_list['Spirits1']=award_list['Spirits1'].fillna(0)
# award_list['CC1']=award_list['CC1'].fillna(0)
# award_list['BAFTA2']=award_list['BAFTA2'].fillna(0)
# award_list['Globes2']=award_list['Globes2'].fillna(0)
# award_list['SAG2']=award_list['SAG2'].fillna(0)
# award_list['Spirits2']=award_list['Spirits2'].fillna(0)
# award_list['CC2']=award_list['CC2'].fillna(0)
# award_list['Oscar2']=award_list['Oscar2'].fillna(0)
award_list = award_list.drop(['Oscar0','Oscar1'],axis=1)
award_list=award_list.drop_duplicates()
award_list.head()
| name | year | BAFTA0 | BAFTA1 | BAFTA2 | Globes0 | Globes1 | Globes2 | SAG0 | SAG1 | SAG2 | Spirits0 | Spirits1 | Spirits2 | CC0 | CC1 | CC2 | Oscar2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Hugh Grant | 1995 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | Terence Stamp | 1995 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | Tom Hanks | 1995 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 3 | John Travolta | 1995 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | Nigel Hawthorne | 1996 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
award_list[award_list['name']=='Leonardo DiCaprio']
| name | year | BAFTA0 | BAFTA1 | BAFTA2 | Globes0 | Globes1 | Globes2 | SAG0 | SAG1 | SAG2 | Spirits0 | Spirits1 | Spirits2 | CC0 | CC1 | CC2 | Oscar2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 47 | Leonardo DiCaprio | 2005 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 58 | Leonardo DiCaprio | 2007 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 97 | Leonardo DiCaprio | 2014 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 117 | Leonardo DiCaprio | 1998 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 130 | Leonardo DiCaprio | 2003 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 141 | Leonardo DiCaprio | 2009 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 146 | Leonardo DiCaprio | 2012 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
# Machine Learning Imports
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
from sklearn.learning_curve import learning_curve
# For evaluating our ML results
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
# Dataset Import
import statsmodels.api as sm
%matplotlib inline
X = award_list.drop(['name','year','Oscar2'],axis=1)
y = award_list.Oscar2
y.head()
0 0
1 0
2 1
3 0
4 0
Name: Oscar2, dtype: float64
# Create LogisticRegression model
log_model = LogisticRegression(C=1.0, penalty='l2', tol=1e-6)
# Fit our data
log_model.fit(X,y)
# Check our accuracy
log_model.score(X,y)
0.96590909090909094
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",alpha=0.6,linewidth=4,
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="navy",alpha=0.6,linewidth=4,
label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show()
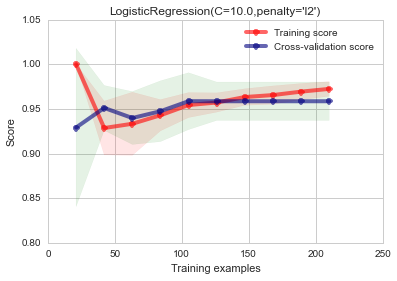
plot_learning_curve(LogisticRegression(C=20.0, penalty='l2'), "LogisticRegression(C=10.0,penalty='l2')",
X, y, ylim=(0.8, 1.05),
train_sizes=np.linspace(.1, 1, 10))
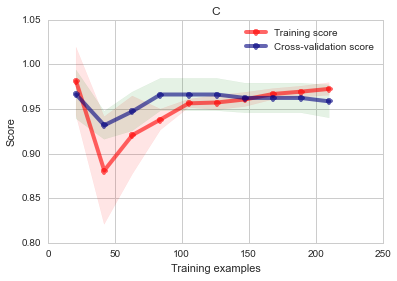
from sklearn.grid_search import GridSearchCV
GS = GridSearchCV(LogisticRegression(),
param_grid={"C": [0.1, 1.0, 5.0, 10.0, 20.0],"penalty":['l1','l2']})
print "Chosen parameter on 100 datapoints: %s" % GS.fit(X, y).best_params_
plot_learning_curve(GS, "C",
X, y, ylim=(0.8, 1.05),
train_sizes=np.linspace(.1, 1, 10))
GS.best_estimator_
Chosen parameter on 100 datapoints: {'penalty': 'l1', 'C': 1.0}
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l1', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
# Globes
colist=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2']
X_test = DataFrame(columns=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
win = Series([0,0,0,0,0,1,0,0,0,0,0,0,0,0,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,0,0,0,0,0,0,0,0,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,0,0,0,0,0,0,0,0,0],index=colist)
X_test = X_test.append(win,ignore_index=True)
log_model = LogisticRegression(C=1.0, penalty='l1')
log_model.fit(X,y)
log_model.predict_proba(X_test)[:,1]
array([ 0.32155716, 0.28428716, 0.28428716])
# Globes - CC
X_test = DataFrame(columns=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
win = Series([0,0,0,0,0,1,0,0,0,0,0,0,0,0,1],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,0,0,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,0,0,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
log_model = LogisticRegression(C=1.0, penalty='l1')
log_model.fit(X,y)
log_model.predict_proba(X_test)[:,1]
array([ 0.48074555, 0.19276261, 0.19276261])
# Globes - CC - SAGs
X_test = DataFrame(columns=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
win = Series([0,0,0,0,0,1,0,0,1,0,0,0,0,0,1],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,0,1,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,0,0,0,1,0,1,0,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
log_model = LogisticRegression(C=1.0, penalty='l1')
log_model.fit(X,y)
log_model.predict_proba(X_test)[:,1]
array([ 0.88804238, 0.05891302, 0.00865326])
# Globes - CC - SAGs - BAFTA
X_test = DataFrame(columns=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
win = Series([0,0,1,0,0,1,0,0,1,0,0,0,0,0,1],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,1,0,0,1,0,0,1,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,1,0,0,1,0,1,0,0,0,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
log_model = LogisticRegression(C=1.0, penalty='l1')
log_model.fit(X,y)
log_model.predict_proba(X_test)[:,1]
array([ 0.88809967, 0.05896 , 0.00865978])
# Globes - CC - SAGs - BAFTA - Spirits
X_test = DataFrame(columns=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
win = Series([0,0,1,0,0,1,0,0,1,1,0,0,0,0,1],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,1,0,0,1,0,0,1,0,1,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
win = Series([0,1,0,0,1,0,1,0,0,1,0,0,0,1,0],index=['B0','B1','B2','G0','G1','G2','S0','S1','S2','SP0','SP1','SP2','C0','C1','C2'])
X_test = X_test.append(win,ignore_index=True)
log_model = LogisticRegression(C=1.0, penalty='l1')
log_model.fit(X,y)
log_model.predict_proba(X_test)[:,1]
array([ 0.87316036, 0.0515114 , 0.0075178 ])
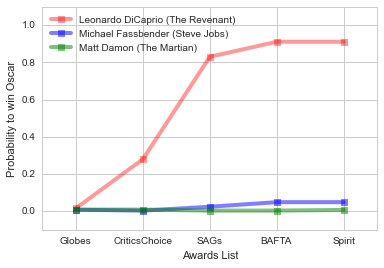
matrix = DataFrame(columns=['name','Globes','CriticsChoice','SAGs','BAFTA','Spirit'])
nominee = Series(['Leonardo DiCaprio',0.0157,0.279,0.83,0.911,0.911],index=['name','Globes','CriticsChoice','SAGs','BAFTA','Spirit'])
matrix = matrix.append(nominee,ignore_index=True)
nominee1 = Series(['Michael Fassbender',0.008,0.003,0.024,0.0486,0.0486],index=['name','Globes','CriticsChoice','SAGs','BAFTA','Spirit'])
matrix = matrix.append(nominee1,ignore_index=True)
nominee2 = Series(['Matt Damon',0.0086,0.0087,0.0033,0.0033,0.0068],index=['name','Globes','CriticsChoice','SAGs','BAFTA','Spirit'])
matrix = matrix.append(nominee2,ignore_index=True)
matrix
| name | Globes | CriticsChoice | SAGs | BAFTA | Spirit | |
|---|---|---|---|---|---|---|
| 0 | Leonardo DiCaprio | 0.0157 | 0.2790 | 0.8300 | 0.9110 | 0.9110 |
| 1 | Michael Fassbender | 0.0080 | 0.0030 | 0.0240 | 0.0486 | 0.0486 |
| 2 | Matt Damon | 0.0086 | 0.0087 | 0.0033 | 0.0033 | 0.0068 |
plt.figure()
plt.plot(nominee[1:], 's-', color="r",alpha=0.4,linewidth=4,
label="Leonardo DiCaprio (The Revenant)")
plt.plot(nominee1[1:], 's-', color="b",alpha=0.5,linewidth=4,
label="Michael Fassbender (Steve Jobs)")
plt.plot(nominee2[1:], 's-', color="g",alpha=0.5,linewidth=4,
label="Matt Damon (The Martian)")
labels=['Globes','CriticsChoice','SAGs','BAFTA','Spirit']
plt.xticks([0,1,2,3,4], labels)
plt.xlabel("Awards List")
plt.ylabel("Probability to win Oscar")
plt.xlim(-0.5,4.5)
plt.ylim(-0.1,1.1)
plt.legend(loc="best")
plt.grid("on")
plt.show()